Empowering Scalability: Harnessing the Power of CQRS for High-Performance Systems
In the world of software architecture and design patterns, the Command Query Responsibility Segregation (CQRS) pattern has gained popularity for its ability to improve system scalability, maintainability, and performance.
In this blog, we will explore what CQRS is, why it is essential, how to implement it, and the advantages it offers to developers and organizations.
What is CQRS?
CQRS stands for Command Query Responsibility Segregation. It’s an architectural pattern that suggests separating the read and write operations for a given data model. In traditional systems, a single model is often used for both read and write operations. CQRS advocates splitting this model into two distinct parts: one for handling commands (writes) and another for queries (reads).
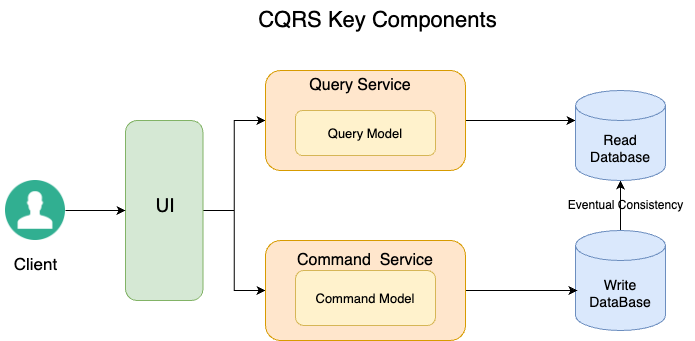
Why CQRS
Now that we know what CQRS is, let’s delve into the reasons why this pattern is beneficial:
1.Scalability: CQRS empowers you to scale your read and write components independently, offering a flexible solution to handle varying workloads. To elaborate further, you can deploy multiple instances of your read components or distribute your read databases across servers. This allows you to efficiently manage the increased demand on read operations, which often outnumber write operations. By decoupling the scaling of read and write functionalities, you can optimize resource allocation, ensuring responsive and efficient performance even under heavy loads.
2.Performance Optimization: CQRS enables you to tailor your read models for optimal performance. This includes designing and structuring your read models to cater specifically to the needs of querying operations. By separating read and write concerns, you have the freedom to fine-tune your read models independently, implementing caching mechanisms or denormalization strategies to achieve faster response times. This level of optimization contributes to an overall improvement in system performance and user experience 3.Maintainability: CQRS promotes cleaner code by enforcing a clear separation of concerns. This makes it easier to maintain and evolve your system over time, as you have isolated the logic for handling commands and queries.
4.Flexibility: CQRS allows you to use different data storage technologies for your read and write models. For example, you can use a relational database for writes and a NoSQL database for reads, optimizing each for its respective workload.
CQRS Use Cases: Domains that Benefit from Command Query Responsibility Segregation
E-commerce:
Managing product listings, inventory updates, order placements, and user accounts often involves distinct read and write concerns.
Finance and Banking:
Handling transactions, managing account balances, and generating financial reports may have different requirements for command and query processing. Healthcare:
Logistics and Supply Chain:
Tracking shipments, managing warehouse inventory, and processing orders involve a mix of write and read operations that can benefit from separate optimization.
Social Media:
Social platforms may have intense write operations when users create content or engage in real-time communication. The read side is crucial for displaying user profiles, feeds, and recommendations.
Synchronizing Data in CQRS: Bridging the Divide between Read and Write Databases
Now that we have explored the essence of CQRS and its benefits in separating the concerns of reading and writing data, the next pivotal question arises: How do we ensure that the data remains synchronized between the distinct read and write databases?
-
Embracing Event Sourcing: CQRS often goes hand in hand with the concept of event sourcing. Events, representing state changes, are stored in an event store on the write side. On the read side, we employ event handlers that subscribe to these events, updating the read database accordingly. This asynchronous process allows for the decoupling of the write and read operations, ensuring a more responsive and scalable system. The write-side components emit events when changes occur. These events are then captured and processed by event handlers on the read side. These handlers play a crucial role in updating the read database based on the evolving state of the system. By executing asynchronously, event handlers prevent bottlenecks in the write-side processing.
-
CQRS utilises the concept of eventual consistency: While the write side updates its data immediately, the read side might experience a slight delay. This temporary inconsistency between the two sides is a trade-off that allows for improved system responsiveness. Users should be aware of this characteristic and design their applications to gracefully handle it.
-
Database Replication: For scenarios demanding real-time or near-real-time synchronization, database replication becomes a valuable factor. Replicating data from the write database to the read database ensures that changes are swiftly reflected in the query-optimized read store. This replication can occur synchronously or asynchronously, depending on the performance requirements of the system.
-
Materialized Views for Performance: Materialized views offer an optimized solution for complex queries on the read side. By precomputing and storing results based on events from the write side, materialized views provide rapid access to information without the need for intensive processing during query execution.
-
Message Brokers as Intermediaries: The use of message brokers, such as Apache Kafka or RabbitMQ, provides a resilient and scalable communication channel between the write and read sides. Events emitted by the write side are transmitted through the message broker, ensuring loose coupling and facilitating robust data synchronization.
-
Idempotent Operations: To enhance the reliability of data synchronization, it’s crucial to design systems that handle idempotent operations gracefully. Ensuring that the same event can be safely applied multiple times without adverse effects becomes imperative, particularly when replaying events.
-
Monitoring and Error Handling: Implementing robust monitoring and error-handling mechanisms is paramount. Logs and alerts can help detect and address issues promptly, guaranteeing the continued integrity of the data synchronization process.Additionally, consider incorporating retry queues for enhanced error handling in the context of CQRS. Retry queues offer a valuable mechanism to automatically reprocess failed or delayed messages, promoting system resilience and minimizing the impact of transient errors. This proactive approach ensures that the data synchronization process can recover gracefully from hiccups and maintain its reliability over time.
In short , while CQRS introduces a clear and powerful separation of concerns in data management, the synchronization of data between the write and read sides requires careful consideration and thoughtful implementation.
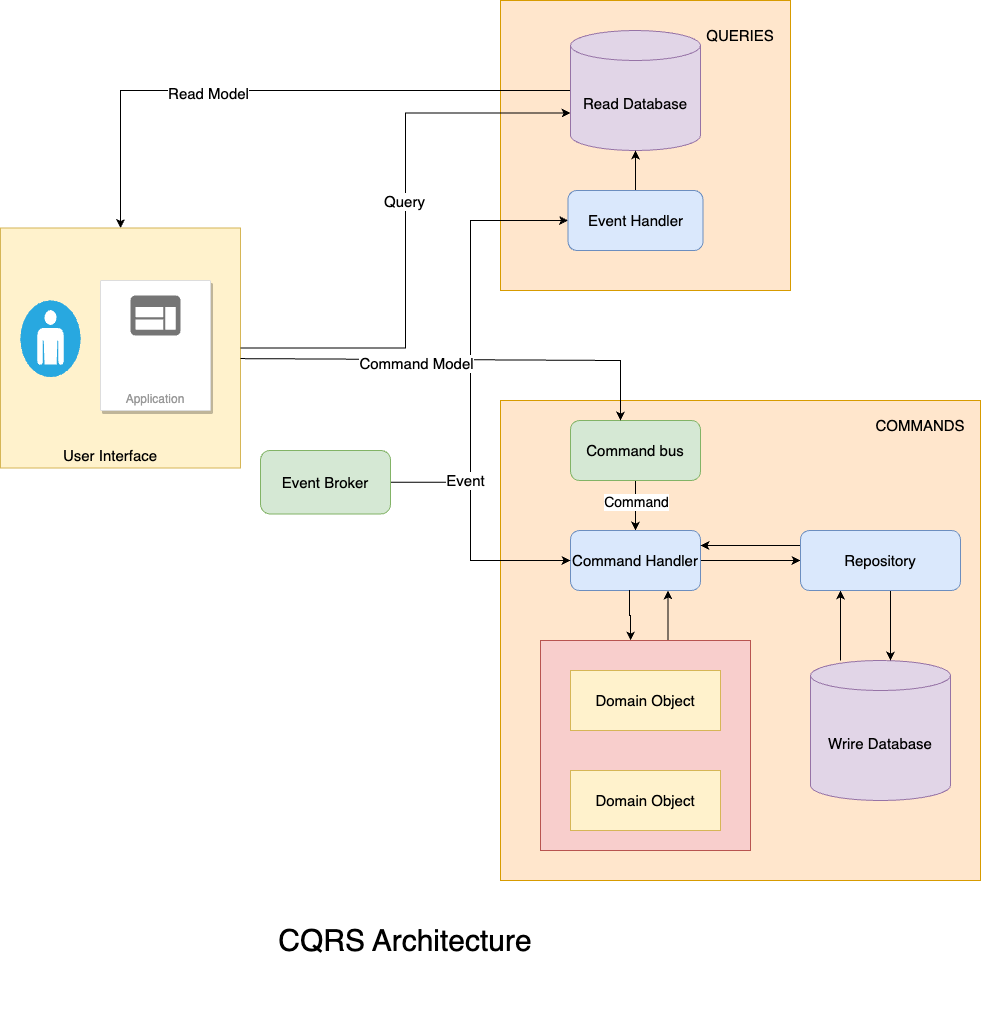
Designing a CQRS System
-
Identify Command and Query Models
-
Command Model:
- Focuses on handling write operations.
- Contains entities and logic for modifying the system’s state. * #### Query Model:
- Focuses on handling read operations.
- Contains entities and logic optimized for querying and data retrieval.
-
-
Define Command and Query Handlers
-
Command Handlers:
- Implement the logic to process and execute command requests.
- Update the state of the system based on the received commands. * #### Query Handlers:
- Implement the logic to process and execute query requests.
- Retrieve data from the system to fulfill read requests.
-
-
Introduce Aggregates for Consistency
- Aggregates:
- Define clusters of related entities that form a consistency boundary.
- Ensure atomicity and data consistency for operations within the aggregate.
-
Implement Domain Models
- Domain Models:
- Represent the core entities and business logic of the system.
- Enforce business rules and encapsulate behavior.
-
Establish Asynchronous Communication
-
Event Sourcing:
- Record events as a log of state-changing operations.
- Provides a historical view of changes and supports recovery. * #### Message Queues:
- Implement asynchronous communication between components.
- Enhances system responsiveness and scalability.
-
-
Optimize for Read and Write Operations
-
Write-Side Optimization:
- Optimize for high-throughput write operations.
- Ensure efficient handling of command requests. * #### Read-Side Optimization:
- Optimize for complex querying and data retrieval.
- Implement caching and other optimizations to enhance read performance.
-
-
Address Consistency Challenges
- Eventual Consistency:
- Accept that consistency may not be instantaneous across all parts of the system.
- Implement strategies to handle eventual consistency, such as background processes for updates.
-
Monitor and Tune
-
Monitoring:
- Implement monitoring solutions to track system performance.
- Monitor command and query execution times, event processing, and system health. * #### Tuning:
- Continuously analyze and tune the system for optimal performance.
- Adjust resource allocation, database indexes, and caching strategies based on monitoring insights.
-
Implementing CQRS in Spring Boot
Let’s create a simple Spring Boot application to demonstrate the CQRS pattern. In this example, we’ll focus on a hypothetical “Task Management” system.
├── src
│ ├── main
│ │ ├── java
│ │ │ └── com.example.cqrs
│ │ │ ├── command
│ │ │ │ ├── CreateTaskCommand.java
│ │ │ │ └── TaskCommandHandler.java
│ │ │ ├── query
│ │ │ │ ├── TaskDetailsQuery.java
│ │ │ │ └── TaskQueryHandler.java
│ │ │ ├── domain
│ │ │ │ └── Task.java
│ │ │ ├── Application.java
│ │ │ └── TaskController.java
│ │ └── resources
│ └── test
1. Command Model:
The CreateTaskCommand class encapsulates the data needed to create a new task, such as the task title
// CreateTaskCommand.java
public class CreateTaskCommand {
private String title;
// other fields, getters, setters
}
2. Command Handler:
The TaskCommandHandler class is responsible for executing the command, creating a new task, and storing it in the database.
// TaskCommandHandler.java
@Service
public class TaskCommandHandler {
@Autowired
private TaskRepository taskRepository;
public void handle(CreateTaskCommand command) {
Task task = new Task();
task.setTitle(command.getTitle());
// set other fields
taskRepository.save(task);
}
}
3. Query Model:
he TaskDetailsQuery class represents a query for fetching details of a specific task, identified by its unique identifier (taskId).
// TaskDetailsQuery.java
public class TaskDetailsQuery {
private Long taskId;
// other fields, getters, setters
}
4. Query Handler:
The TaskQueryHandler class handles the execution of the query, retrieving task details from the database.
// TaskQueryHandler.java
@Service
public class TaskQueryHandler {
@Autowired
private TaskRepository taskRepository;
public TaskDetailsQueryResult handle(TaskDetailsQuery query) {
Optional<Task> task = taskRepository.findById(query.getTaskId());
return task.map(TaskDetailsQueryResult::new).orElse(null);
}
}
5. Domain Model:
The Task class represents the domain model for a task, including fields such as id (unique identifier) and title. It is annotated with @Entity for JPA mapping
// Task.java
@Entity
public class Task {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
// other fields, getters, setters
}
6. Controller:
The TaskController class exposes RESTful endpoints for interacting with tasks. The POST /tasks endpoint allows the creation of a new task by handling CreateTaskCommand requests. The GET /tasks/{taskId} endpoint allows the retrieval of task details by handling TaskDetailsQuery requests.
// TaskController.java
@RestController
@RequestMapping("/tasks")
public class TaskController {
@Autowired
private TaskCommandHandler taskCommandHandler;
@Autowired
private TaskQueryHandler taskQueryHandler;
@PostMapping
public ResponseEntity<Void> createTask(@RequestBody CreateTaskCommand command) {
taskCommandHandler.handle(command);
return new ResponseEntity<>(HttpStatus.CREATED);
}
@GetMapping("/{taskId}")
public ResponseEntity<TaskDetailsQueryResult> getTaskDetails(@PathVariable Long taskId) {
TaskDetailsQuery query = new TaskDetailsQuery();
query.setTaskId(taskId);
TaskDetailsQueryResult result = taskQueryHandler.handle(query);
return ResponseEntity.ok(result);
}
}
Query Result:
The TaskDetailsQueryResult class represents the result of a task details query, providing a structured response.
// TaskDetailsQueryResult.java
public class TaskDetailsQueryResult {
private Long id;
private String title;
// other fields, getters, setters
public TaskDetailsQueryResult(Task task) {
this.id = task.getId();
this.title = task.getTitle();
// set other fields
}
}
These classes work together to demonstrate a basic CQRS implementation in the context of a simple “Task Management” system using Spring Boot. The primary goal is to showcase how CQRS can be employed to separate the responsibilities of handling commands (write operations) and queries (read operations), leading to a more modular and scalable architecture.
Limitations:
1.Increased Complexity:
Introducing CQRS often results in a more complex system architecture. Developers need to manage separate read and write models, implement event handling, and synchronize data between the two models. This complexity can make the system harder to understand and maintain.
2.Eventual Consistency:
CQRS introduces eventual consistency, meaning that there might be a delay between the time a write operation occurs and when the read model is updated. This inconsistency can be challenging for applications that require immediate and fully consistent query results. Data Synchronization Challenges:
Keeping the read and write models in sync can be complex. Developers need to implement mechanisms to handle data synchronization and address issues such as race conditions and concurrency conflicts.
3.Operational Overhead:
Managing and operating a system based on CQRS may require additional infrastructure and operational considerations. Event sourcing, in particular, introduces challenges related to event storage, replaying events, and managing event versioning.
4.Consistency Challenges in Distributed Systems:
In distributed systems, achieving strong consistency across read and write models can be challenging. Developers may need to choose between eventual consistency and investing in more complex distributed transaction mechanisms.
5. Increased Resource Usage:
Maintaining separate read and write models may lead to increased resource usage, especially in scenarios where frequent updates to the read model are necessary. This can impact scalability and resource efficiency.
Conclusion
In conclusion, Command Query Responsibility Segregation (CQRS) is a nuanced and potent design pattern that has significantly influenced the architecture of modern software systems. While it finds application in diverse domains such as e-commerce, finance, and collaborative tools, the adoption of CQRS comes with its challenges. Navigating the complexities and trade-offs requires a thoughtful approach, and you must weigh the benefits against the learning curve and increased intricacie. As technology continues to evolve, CQRS stands as a valuable tool, offering a strategic approach to building responsive, scalable, and adaptable software solutions.
Thanks For Reading!