Must Know Concepts of System Design
•
• Engineering

System design is the process of defining the architecture, interfaces, and data for a system that satisfies specific requirements. It requires a systematic approach and requires you to think about everything in infrastructure, from the hardware and software, all the way down to the data. These decisions are required to be taken carefully keeping in mind not only the Functional Requirements but also the NFRs Scalability, Reliability, Availability, and Maintainability.
Let’s discuss some very important concepts about designing a system every developer should be aware of.
1. Distributed Cache
A distributed cache is a system that pools together the random-access memory (RAM) of multiple networked computers into a single in-memory data store used as a data cache to provide fast access to data. Distributed caches are especially useful in environments with high data volume and load.
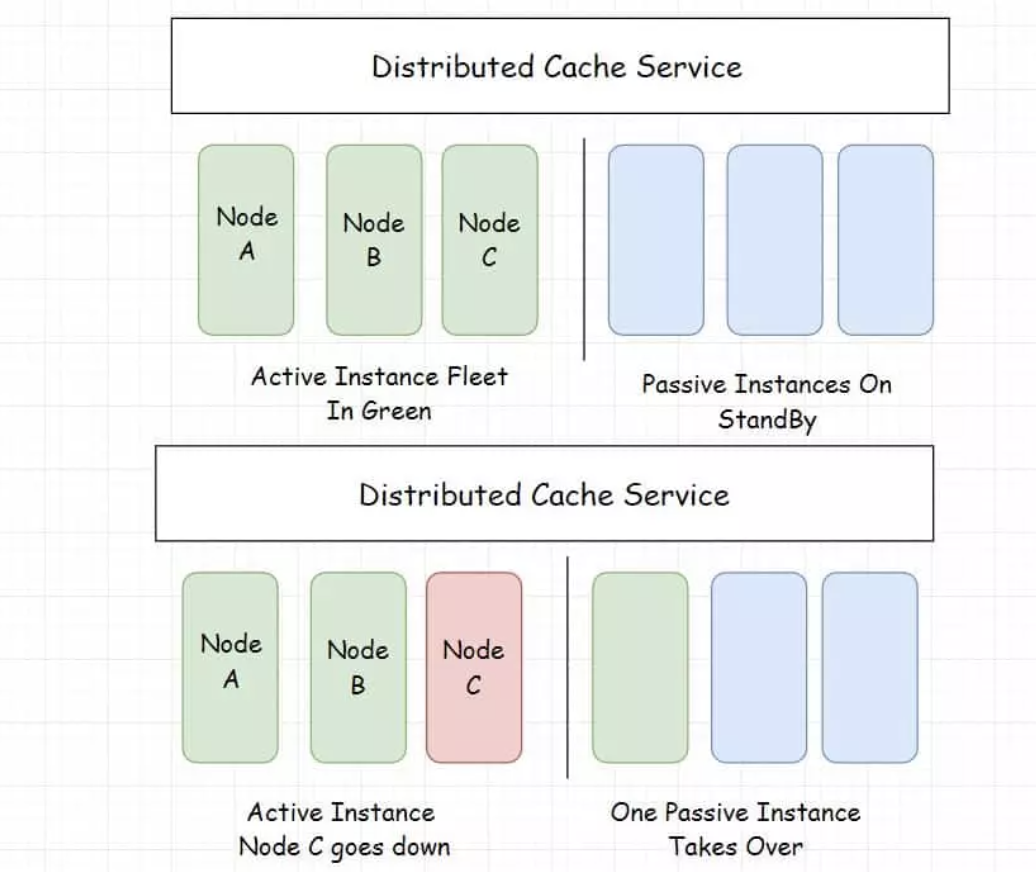
Popular use cases for Distributed cache:
· Storing web session data
· Application acceleration
· Decreasing network usage/costs
· Extreme scaling
Some of the widely used distributed caches are Redis, Hazelcast and Memcached.
2. Distributed Messaging Queues
A distributed messaging queue is used to send messages between distributed components of a system. Most of the messaging patterns follow the publish-subscribe model where the senders of the messages are called publishers and those who want to receive the messages are called subscribers.
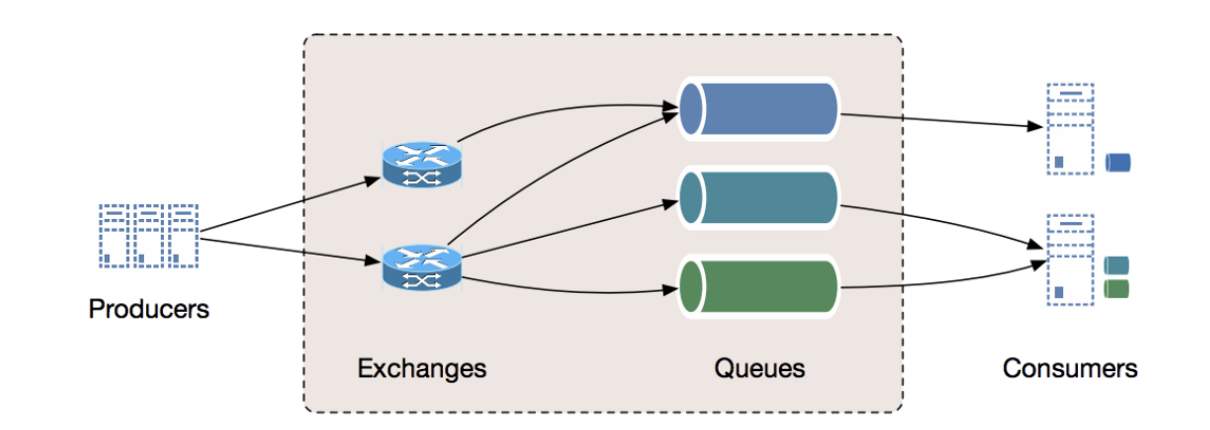
Some benefits of using a distributed messaging queue are:
· We can quickly scale and improve performance depending on live traffics.
· Many message servers have an in-built setup for replications to provide fault-tolerant and durable data.
It provides the benefits of reliability, scalability, and persistence.
Some of the popular distributed messaging queues are Kafka, ActiveMQ, and Kestrel.
3. Distributed File System
A distributed file system, or DFS, is a file system that spans across multiple file servers or multiple locations. The data is accessed and processed as if it was stored on the local client machine. The DFS makes it convenient to share information and files among users on a network in a controlled and authorized way.
Examples include Hadoop Distributed File System(HADOOP), and Ceph.
4. Distributed Databases
With distributed databases, data is physically stored across multiple sites(either on the same network or on entirely different networks) and independently managed.
· Distributed databases have the advantage of modular development, which means we can add a computer and local data to the distributed system anytime without interruption.
· They are also fault-tolerant and continue to function at reduced performance until the error is fixed.
Distributed databases can be homogenous(all the physical locations have the same underlying hardware and run the same operating systems and database applications) or heterogenous(the hardware, operating systems, or database applications may be different at each location).
Though there are many distributed databases to choose from, some examples of distributed databases include Apache Ignite, Apache Cassandra, Apache HBase, and Google Cloud Spanner.
5. Load Balancer
A load balancer is a system that acts as a reverse proxy and distributes network or application traffic across a number of servers. It helps in increasing the capacity (concurrent users),reliability and availability of applications and websites for users.
It provides benefits like predictive analytics that determine traffic bottlenecks before they happen.
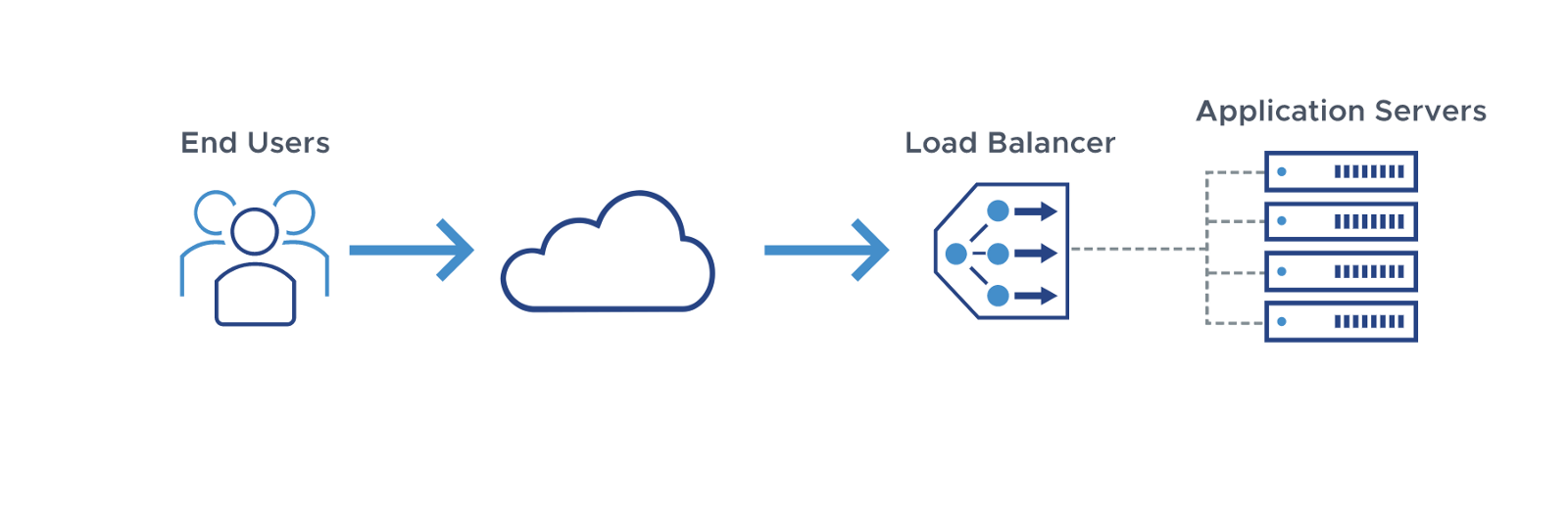
Examples of some load balancers are Nginx, HAProxy, Kemp Loadmaster.
6. Distributed Coordination System
The distributed coordination system handles the communication and cooperation between processes. It is a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems.
Most commonly used distributed coordination system is Apache Zookeeper.
7. Metrics, Monitoring and Alerting
These are used to monitor the health and performance of a distributed system and detect and troubleshoot problems. They help you understand trends in usage or behavior, and to understand the impact of changes you make. If the metrics fall outside of your expected ranges, these systems can send notifications to the concerned person to take a look and identify the possible causes.
The types of values you monitor and the information you track will probably change as your infrastructure evolves.
Some example are Prometheus and Datadog.
8. Distributed locks
Distributed locks provide mutually exclusive access to shared resources in a distributed environment.
They are used for two main reasons:
· Efficiency of a system. Taking a lock saves you from unnecessarily doing the same work twice.
· Correctness of data. It prevents from data corruption, data loss, and data inconsistency.
Distributed locks need to decide whether to use an optimistic or a pessimistic locking policy:
· Optimistic locking policies assume that the resource being read will not change while reading it, and therefore do not lock the resource during read operations.
·Pessimistic locking policies assume that the resource being read will change while reading it, and therefore lock the resource during read operations.
An example of distributed lock is Redlock.
9. Distributed Storage
A distributed storage is a system that can split data across multiple physical servers across data centres. Distributed storage can spread files, block storage or object storage across multiple physical servers.
Advantages of a distributed storage are:
· Scalability: the primary motivation for distributing storage is to scale horizontally.
· Redundancy: distributed storage systems can store more than one copy of the same data, for high availability, backup, and disaster recovery purposes.
· Performance: distributed storage can offer better performance than a single server in some scenarios.
Distributed storage is the basis for massively scalable cloud storage systems like Amazon S3 and Microsoft Azure Blob Storage.
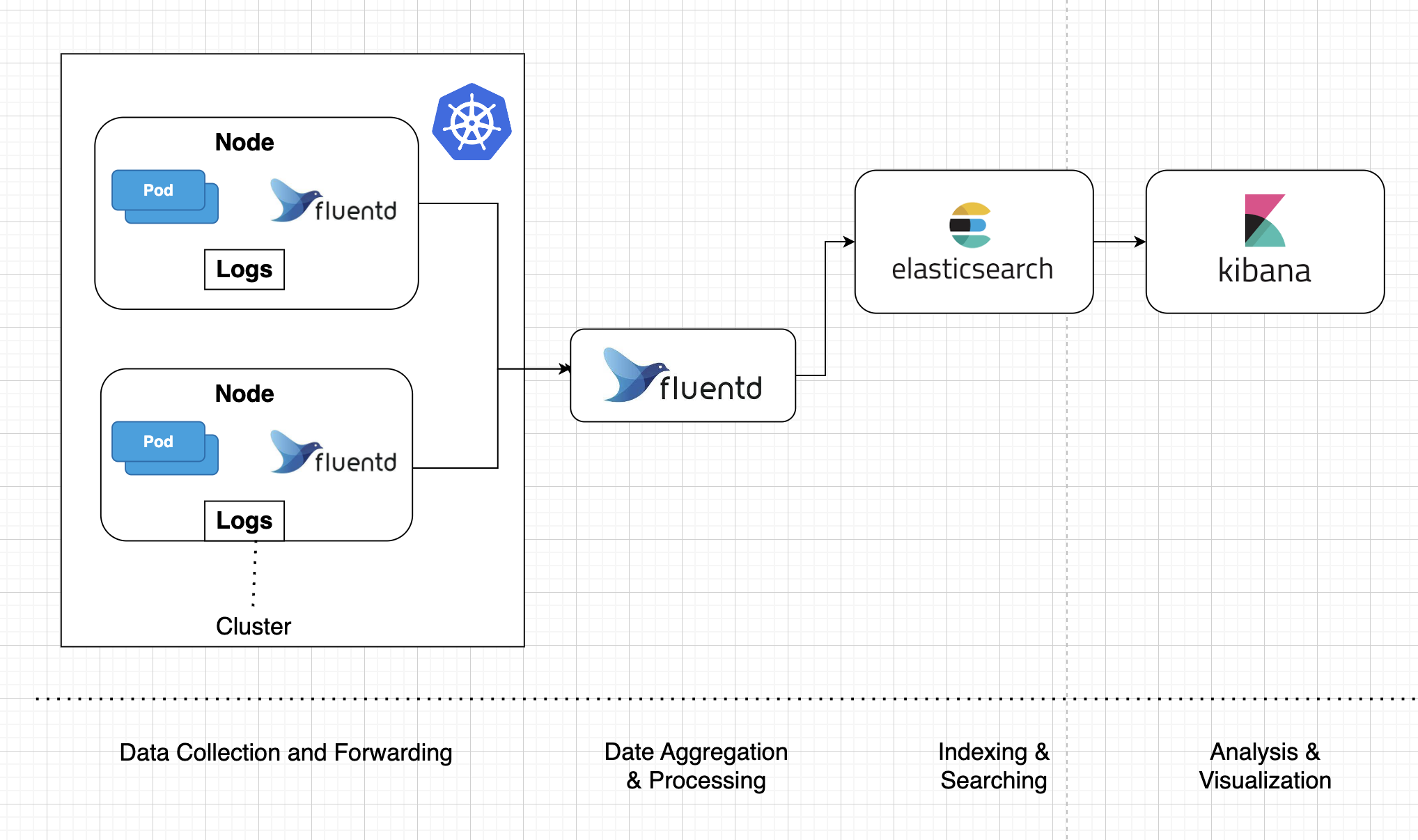
10. Distributed Logging
In distributed systems, each of the applications emits its own logs and often stores them in different locations. With distributed systems, logging is the easy part. What’s much harder is to make sense of this ocean of logs from a logical point of view. This is where centralized logging comes into picture. Centralized logging collects and aggregates logs from multiple services into a central location where they are indexed in a database. The log data can be searched, filtered, and grouped in the log management software by fields like status, host, severity, origin, and timestamp.
11. Stream Processing
Stream processing is a data management technique that involves ingesting a continuous data stream to quickly analyze, filter, transform or enhance the data in real time. Once processed, the data is passed off to an application, data store or another stream processing engine.
Stream processing is key if you want analytics results in real time. Architecturally, stream processing involves a framework of data processing software that sits in between the data source (the producers) and the users of that data (the consumers).
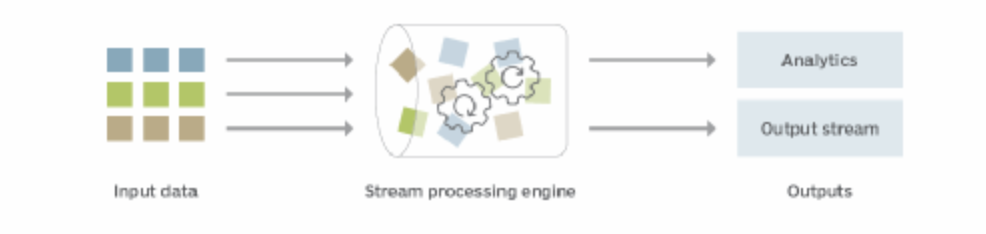
Some Popular stream processing frameworks include Apache Flink and Apache Spark.
12. Full-Text Search
A full-text search is a comprehensive search method that compares every word of the search request against every word within the document or database. It enables users to search for any word in an app or website. The underlying datastructure used here is inverted index, which maps the words or number to its locations in a document or a set of documents.
Lets understand with an example. Imagine you have the following data in a document data store:
[
{
"id": 1,
"name": "Jon Smith",
"description": "Architect, Family"
},
{
"id": 2,
"name": "Frank Jones",
"description": "Family, Basketball"
},
{
"id": 3,
"name": "Jon Frank Whitaker",
"description": "Basketball, Architect"
},
]
If you want to find the information in record with id 2, then any database engine can efficiently retrieve that record for you because they will have an index that looks something like this:
1 => [Location On Disk: 987654]
2 => [Location On Disk: 549877]
3 => [Location On Disk: 654722]
If you need to find all the records that contain the word “Jon” however, the database engine will not be efficient at that query because it will have to scan through each record looking through the entire name field and the entire description field searching for the word “Jon”. A full text search index, on the other hand would look something like this:
"Architect"
1 => [Location On Disk: 987654]
3 => [Location On Disk: 654722]
"Basketball"
2 => [Location On Disk: 549877]
3 => [Location On Disk: 654722]
"Family"
1 => [Location On Disk: 987654]
2 => [Location On Disk: 549877]
"Frank"
2 => [Location On Disk: 549877]
3 => [Location On Disk: 654722]
"Jon"
1 => [Location On Disk: 987654]
3 => [Location On Disk: 654722]
"Jones"
2 => [Location On Disk: 549877]
"Smith"
1 => [Location On Disk: 987654]
"Whitaker"
3 => [Location On Disk: 654722]
Here, you can quickly see that records 1 and 3 contain the text “Jon” and you can efficiently load those records from disk.
Conclusion:
These are the high level concepts which can be used for designing any scalable, highy available and real-time systems.
Thanks for reading!