Unraveling Patterns: Exploring the Fascinating World of Clustering Algorithms
•
• Engineering
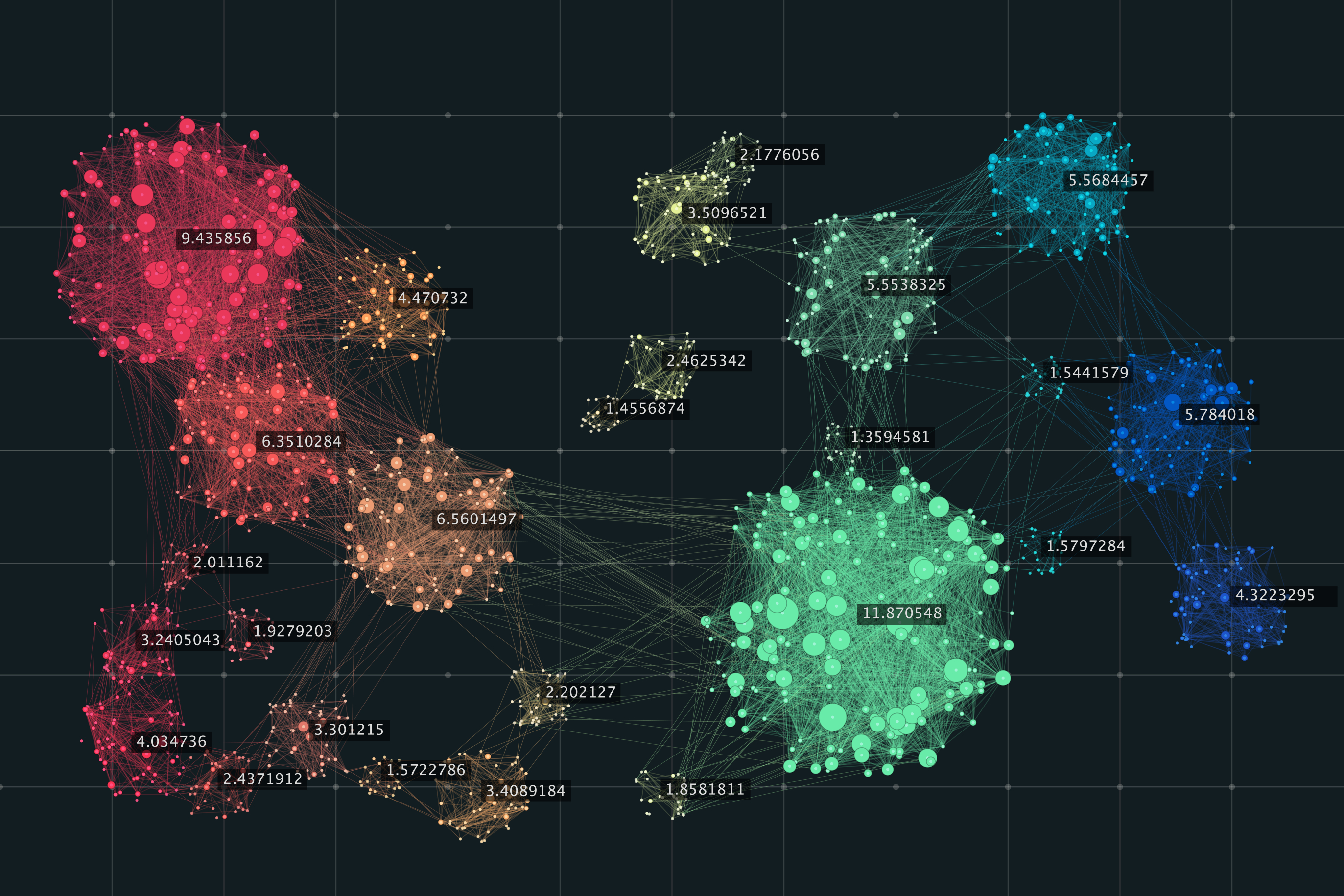
Clustering is a popular technique in machine learning used for grouping data points based on their similarities. It is a type of unsupervised learning method where there is no predefined output variable or label. Instead, the algorithm attempts to discover patterns and structure within the data by grouping similar data points.
What is Clustering? Clustering is a process of grouping a set of data points in such a way that data points in the same group (called a cluster) are more similar to each other than those in other groups. The goal of clustering is to identify patterns or structures within the data that are not immediately apparent.
Classification of Clustering Algorithms
Clustering algorithms can be broadly classified into two categories based on the approach the algorithm takes to group the data.
- Hierarchical Clustering
- Partitioning Clustering
Both of the classifications are explained below.
Hierarchical Clustering
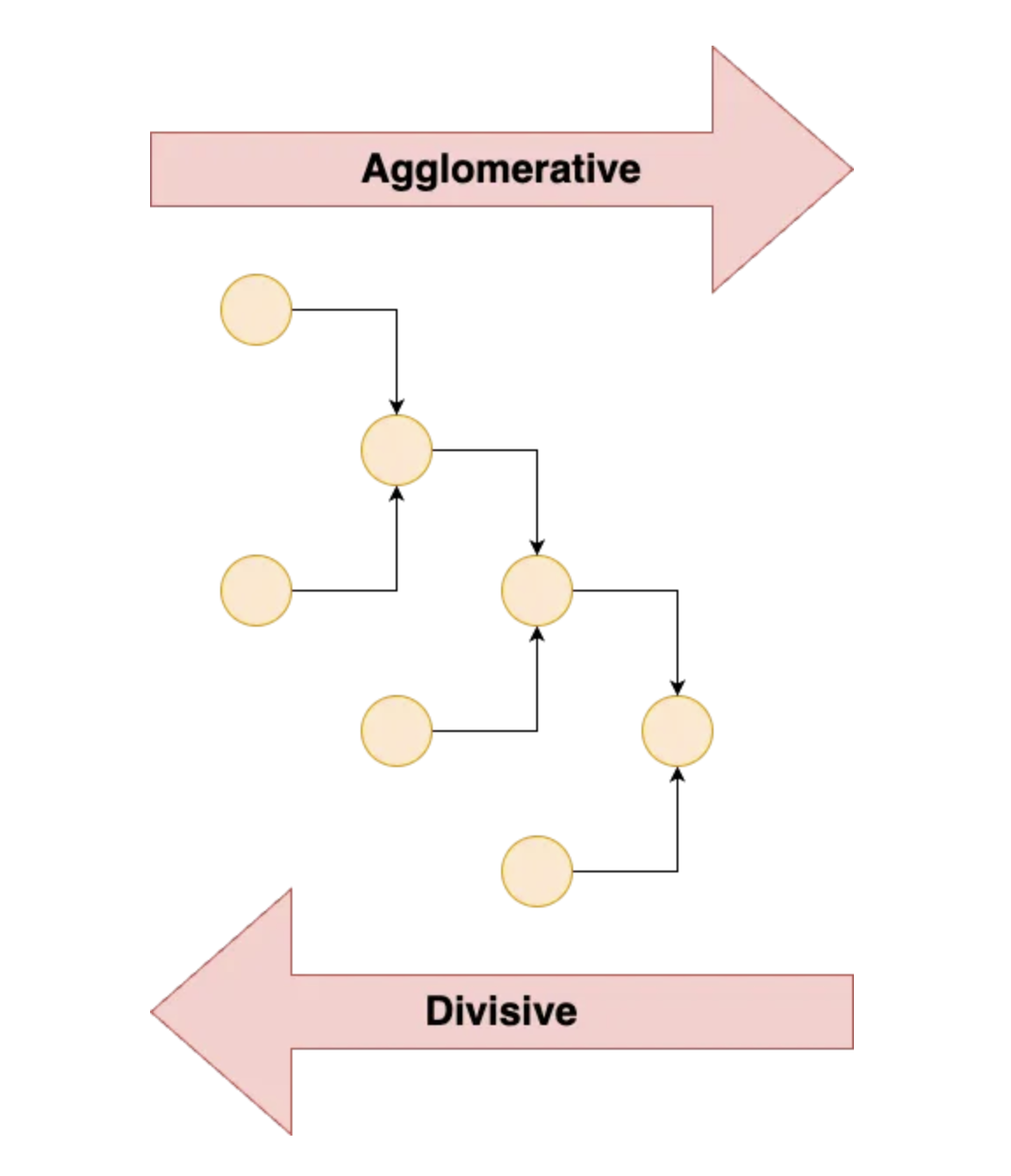
In hierarchical clustering, clusters are formed by recursively dividing the data into smaller clusters until each cluster contains only one data point. There are two types of hierarchical clustering: agglomerative and divisive.
- Agglomerative Clustering begins with each data point as a separate cluster and at each iteration, we merge the closest pair of clusters and repeat this step until only a single cluster is left. Basically, it uses a bottom-up approach. In hierarchical clustering, we have a concept called as proximity matrix which stores the distance between each point. Multiple distance metrics can be used for deciding the closeness of two clusters.
- Euclidean distance: distance((x, y), (a, b)) = √((x — a)² + (y — b)²)
- Manhattan Distance: distance (x1, y1) and (x2, y2) = |x1 — x2| + |y1 — y2|
- Divisive Clustering or the top-bottom approach works in the opposite way. Instead of starting with n clusters, it starts with a single cluster and assigns all the points to that cluster. Therefore, it doesn’t matter if we have 10 0r 1000 data points, all these data points will belong to the same cluster at the beginning. Now at each iteration, we split the farthest point in the cluster and repeat the process until each cluster contains only a single data point.
Partitioning Clustering
In partitioning clustering, the data is divided into non-overlapping clusters by minimizing the distance between the data points within each cluster and maximizing the distance between different clusters. Popular clustering algorithms include several partitioning methods such as k-means, k-medoids, fuzzy c-means etc, working of few of them are explained below:
- K-Means Clustering: K-Means is a widely used clustering algorithm that groups data points into K clusters. The algorithm randomly selects K data points as centroids and then assigns each data point to the nearest centroid. The centroids are then updated by taking the mean of all the data points assigned to them. The K number of means obtained will become the new centroids for each cluster. The process is repeated until convergence. You have to specify the number of clusters — k as an input to the algorithm.
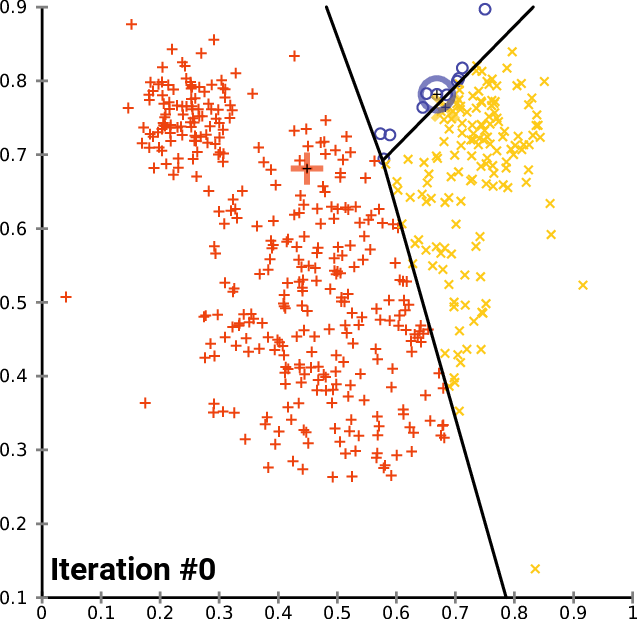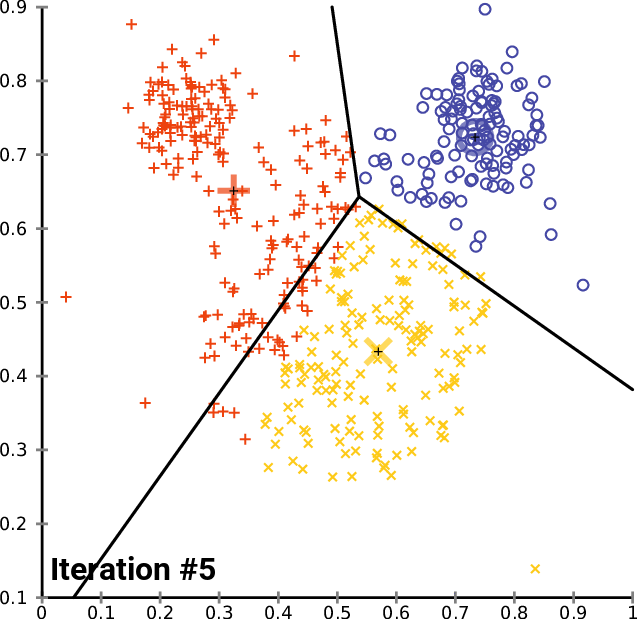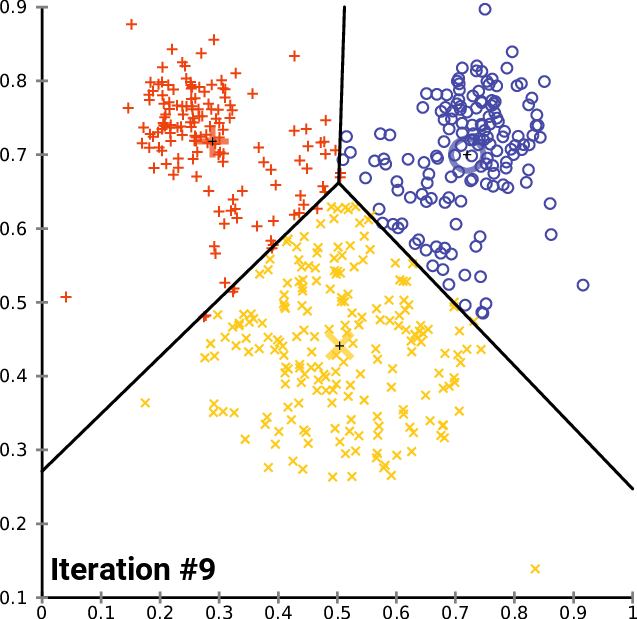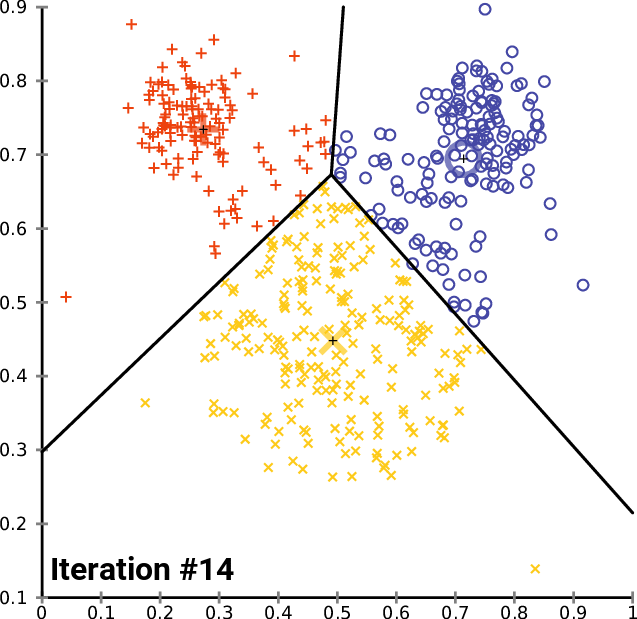 src:https://upload.wikimedia.org/wikipedia/commons/e/ea/K-means_convergence.gif
src:https://upload.wikimedia.org/wikipedia/commons/e/ea/K-means_convergence.gif
-
Hierarchical Clustering: Hierarchical clustering is a bottom-up approach that creates a hierarchical structure of clusters. The algorithm starts by assigning each data point to its own cluster and then iteratively merges the closest pairs of clusters until all data points are in one cluster.
-
Density-Based Clustering: This is a non-parametric clustering method that groups the points which are closely located (high density of points). Density-based clustering is based on the idea that clusters are dense regions of data points separated by areas of lower density. The algorithm identifies areas of high density and expands them until the density falls below a threshold. The resulting regions are clusters.
The algorithm takes the following inputs:
* Epsilon Parameter — ε: Degree of the closeness of points in the same cluster. It is also referred to as the radius of the circle created around each point to check the density
* MinPts: Minimum number of points required inside the circle to be classified as a core point
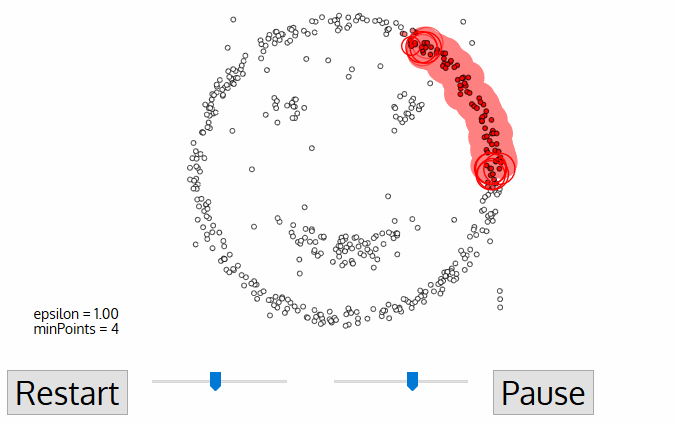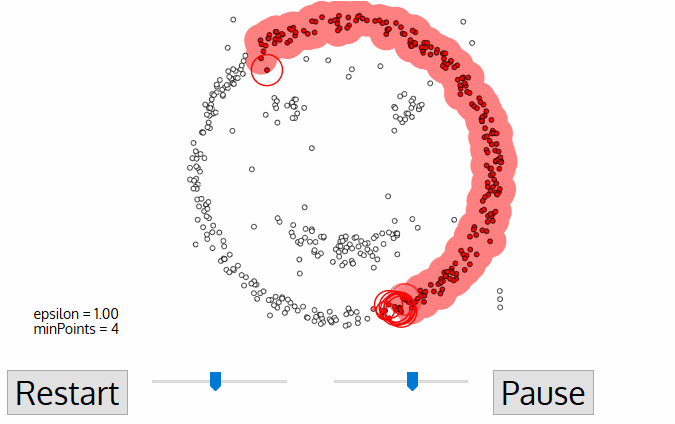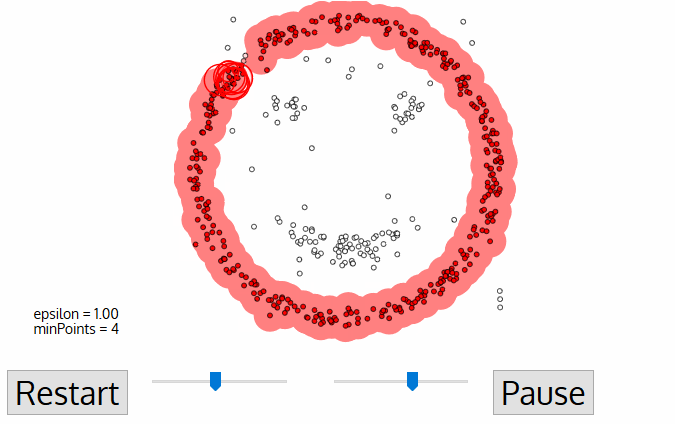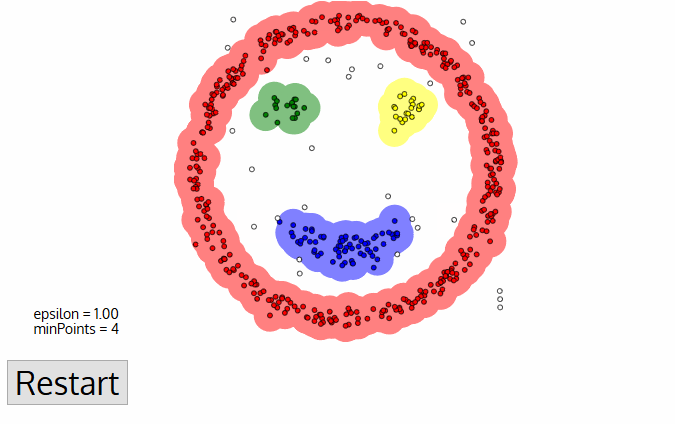 src:https://miro.medium.com/proxy/1*tc8UF-h0nQqUfLC8-0uInQ.gif
src:https://miro.medium.com/proxy/1*tc8UF-h0nQqUfLC8-0uInQ.gif
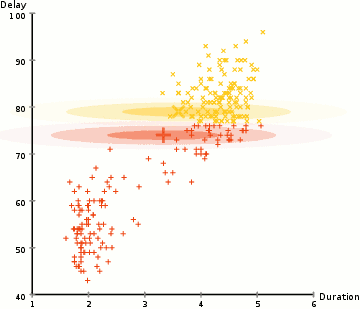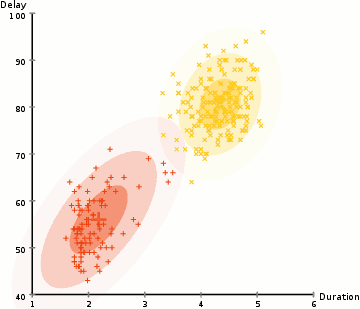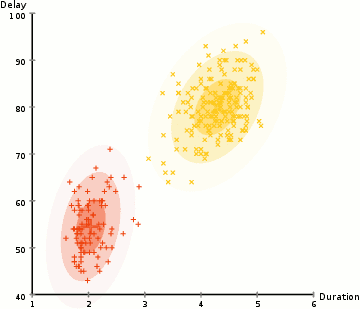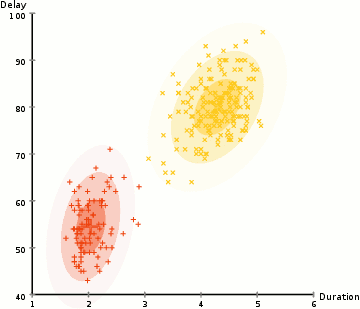
- Expectation-Maximization Clustering (Gaussian Mixture Models): Expectation-Maximization (EM) is a probabilistic clustering algorithm that models each cluster as a probability distribution. The algorithm iteratively assigns data points to clusters based on their probabilities and updates the parameters of the probability distributions.
 src:https://upload.wikimedia.org/wikipedia/commons/6/69/EM_Clustering_of_Old_Faithful_data.gif
src:https://upload.wikimedia.org/wikipedia/commons/6/69/EM_Clustering_of_Old_Faithful_data.gif
From Manual Planning to Smart Clustering: How We Transformed Our Delivery and Collection Workflow
Here, we will give a bit of insight into how we leveraged the clustering to provide better suggestions to our back-office agents to schedule Delivery and Collection orders of vehicles.
Each day we have several delivery and collection orders coming into our pipeline and the branch manager has to manually go and plan a tour and assign an agent to these orders, hence this planning part is an additional burden on them. We have taken a step in the direction of automatic tour planning by leveraging the power of clustering, we try to generate intelligent tour suggestions that the branch manager can review and import.
Our tour generation takes distance and time as the clustering parameter along with our custom set of rules to further refine the suggestions.

We will further keep on refining our recommendations and also try to generate tours based on the available manpower. Also will plan to incorporate an optimized route for a particular tour.
We’re just getting started! stay tuned for updates about the new cool features around the recommendations……..
adios…..