Dask: A parallel data processing python library for large datasets
While conducting data analytics, we often utilize Pandas to perform specific operations on the data in order to extract valuable insights. Initially, when working on data manipulation, I approached it as a data structure problem and did not make use of any built-in Pandas functions. Later, as I delved deeper into Pandas and explored its functions, I discovered that it was significantly faster than manually iterating over the DataFrame (or using the Pandas apply function, which essentially involves iterating over an axis and applying a function) and performing operations on individual rows. Curious about why these built-in functions were faster, I conducted some research and found that Pandas uses NumPy under the hood, which contributes to its speed. When can convert our dataframe to numpy vectors and perform mathematical operations on these vectors if we want our code to be fast. Writing code to perform these vector calculations is significantly harder when lots of operations are involved and sometimes python functions are easier and faster to implement.
In a specific use case involving a DataFrame was large, I had to iterate over the DataFrame and perform operations. This significantly slowed down my code. Recognizing the need for optimization, I began exploring ways to make the iteration (or the apply function) faster. While numerous alternatives were available, one of them was notably simple and easy to use and understand: a library called Dask. Dask parallelizes the process by breaking down the DataFrame into multiple partitions and performing operations on them concurrently.
Dask offers various methods that serve as alternatives to Pandas functions, performing the same operations but in parallel. In today’s computing environment, where most computers have multiple cores and can take advantage of multiple threads, Dask provides a distinct advantage over traditional Pandas.
Dask can be particularly useful when dealing with large datasets that cannot all fit into your RAM at once. By using Dask, you can split the data into multiple tasks, and these tasks can fit into the RAM more efficiently.
Internals
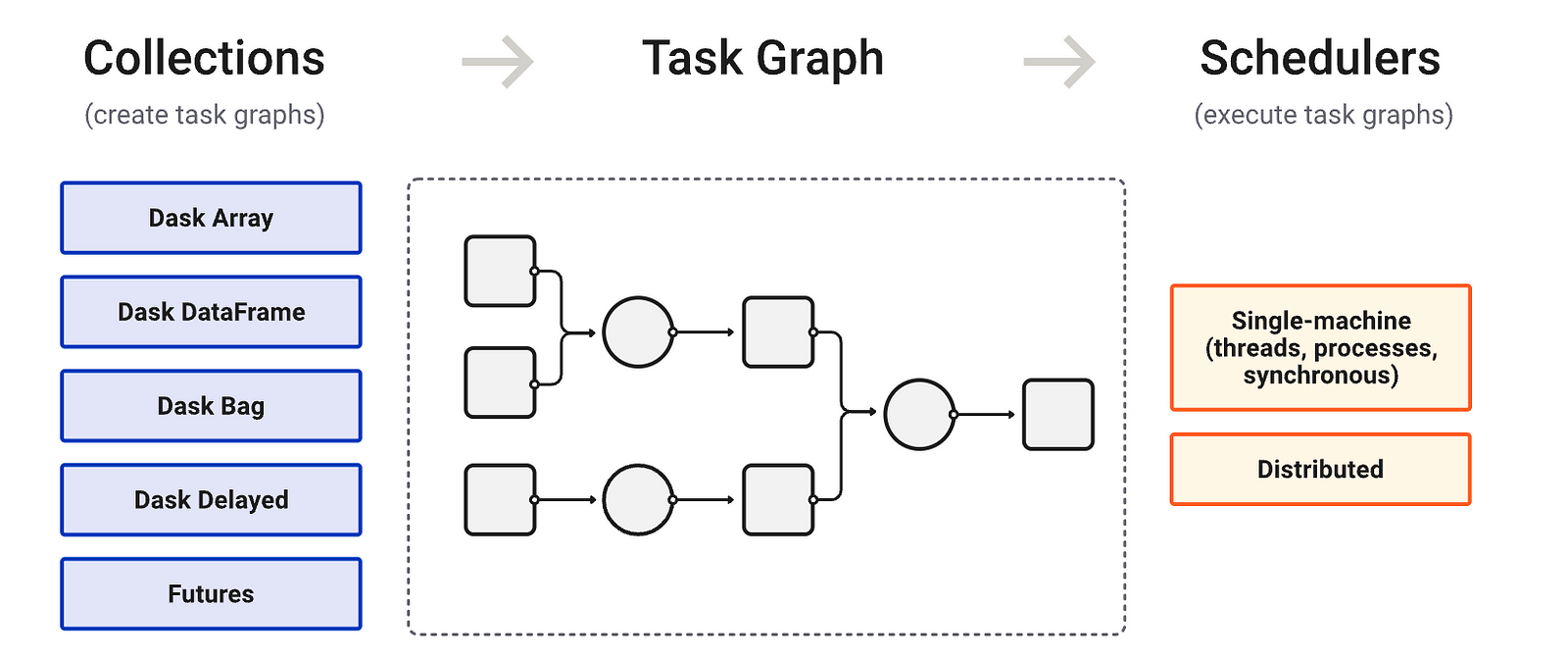
Dask provides us with multiple collections(could be understood as data structures) in which we can store data. This data is converted into a Task Graph and these tasks in the graph are worked on in parallel by multiple threads present in the system(we can even use Dask in a distributed environment for higher workloads).These task graphs are acyclic in nature and each node can be understood as a python function and each edge as a python object. These nodes can be worked upon by threads, hence achieving parallelism.
Dask basics
Minute level entries had to be generated for multiple vehicles and for each entry some processing had to be done. When multiple vehicles were involved, the number of entries was a lot for my system to process. So I tried it on an AWS EC2 instance and yet it was taking a lot of time to process these entries. When the resource utilisation of the EC2 instance was checked it still had lots more to give as only one core was utilised so parallelisation could work and all of the resources at hand could be used.
After some research, I found that Dask Dataframes could be used and the advantage was that i could easily convert a pandas dataframe to a Dask Dataframe.
import dask.dataframe as dd
dask_df = dd.from_pandas(pandas_df, npartitions=n)
We can create partitions in our dataset by using the arguments npartitions.
To perform any sort of processing on this dataframe we can do:
dask_df = dask_df.map_partitions( func )
df = dask_df.compute()
This function can be a lambda function, or a normal function which takes input as a dask dataframe. The partitions created initially will be mapped to the function specified in the map_partitions, the function will take argument of type dask dataframe. For this processing to happen we have to use the compute function, which starts performing the computations and gives us an output , the output will be a pandas dataframe. For optimal performance Dask’s documentation advices to switch between dask and pandas dataframes , we should do this when the computed data from dask data frame is small enough to fit in the RAM easily.
Dask built-in Function example
Dask has a few functions which resemble the conventional pandas functions. Dask.explode is one such function.
pandas.explode: One of the most useful functions that we can relate is the explode function, when we have to create row wise entry for a every element in a list which is present in a row we can use the explode function.
Example from pandas documentation:

Dask has the same function, which is particularly useful when there are multiple lists in the column that you want to explode and the resultant dataframe would be very large in size due to the nature of the function hence dask is useful here.
import dask.dataframe as dd
dask_df = dd.from_pandas(pandas_df, npartitions=n)
dasf_df = dask_df.explode(column)
Results in my use case
Initially to test the advantages of using dask I took a smaller dataset and check how much advantage dask could give me
Using Pandas:

Using Dask:

We can see a 50%+ step up in the total computation time, for a smaller subset of my usecase. In the 2nd case, it can be noticed that cpu time is not the same as wall time, this is because parallelism was used.
Drawbacks
Dask can be useful only if large datasets are used and if the operations that have to be performed is a dask function(or a combination of them).
Insights
Dask can be a very powerful tool when used along with pandas, but it is mainly useful when the data being worked upon is large, for smaller datasets it is better to use pandas and not rely on dask. When using dask it is better to couple it up with pandas and use dask just as an optimisation tool.